Quick links
Quick NewsDescription
Main features
Supported Platforms
Performance
Reliability
Security
Download
Documentation
Live demo
They use it!
Commercial Support
Add-on features
Other Solutions
Contacts
External links
Mailing list archives
Willy TARREAU
2009/08/23 - Quick test of version 1.4-dev2 : barrier of 100k HTTP req/s crossed
Introduction
-
It was my first test since I moved house. I wanted to quickly plug the machines together to see if my work
on version 1.4 went into the right direction, and most importantly was not causing performance drops.
Verdict below confirms it. A new record of 108000 HTTP requests processed per second was broken,
and a new record of 40000 forwarded HTTP requests per second was broken too.
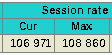
The first test only accepts a new connection, reads the request, parses it, checks an ACL, sends a redirect
and closes. A session rate of 132000 connections per second could even be measured in pure TCP mode, but this
is not very useful :
 .
.
The second test forwards the request to a real server instead, and fetches a 64-byte object :
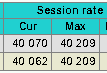
These improvements are due to the ability to tell the system to merge some carefully chosen TCP packets at critical phases of the session. This results in lower number of packets per session, which in turn saves both bandwidth and CPU cycles. The smallest session is now down to 5-6 packets on each side, down from 9 initially.
2009/04/18 - New benchmark of HAProxy at 10 Gbps using Myricom's 10GbE NICs (Myri-10G PCI-Express)
Introduction
-
Precisely one year ago I ran some tests on
the high performance 10GbE NICs that
were donated to me by Myricom. In one year, haproxy has
evolved quite a lot. The I/O subsystem has been completely reworked and it can now
make use of the TCP splicing implemented in Linux 2.6 to avoid copying data in
userspace. This test will show what is possible with TCP splicing now.
Lab setup
-
The lab has almost not changed. One of the two AMD systems was upgraded to a Phenom X4
running at 3 GHz, but that's all. Haproxy will still be run on the intel Core2Duo E8200
at 2.66 GHz. The kernels were updated to 2.6.27-wt5 which is 2.6.27.19 + a few patches
that I need to easily boot those machines from the network. The 2.6.27 kernel includes
support for TCP splicing, for generic Large Receive Offload (LRO) and also includes a
more recent myri10ge driver which now has no problem moving 10 Gbps of traffic
on the AMD boards in both directions. The kernel has received fixes for bugs in the
splicing code that were spotted a few months ago while preparing this test. It seems
everyone is not lucky enough to run tests on such fantastic hardware, so bugs are to be
expected in such configurations ;-)
Hardware / software setup :
| Machine | Role | Mobo | CPU | Kernel | myri drv | myri fw | software |
|---|---|---|---|---|---|---|---|
| AMD2 | Client | | 2.6.27smp-wt5 | 1.4.3-1.358 | 1.4.36 | inject31 | | |
| C2D | Proxy | | 2.6.27smp-wt5 | 1.4.3-1.358 | 1.4.36 | haproxy-1.3.17-12 | | |
| AMD1 | Server | | 2.6.27smp-wt5 | 1.4.3-1.358 | 1.4.36 | httpterm 1.3.0 | |
The tests are quite simple. An HTTP request generator runs on the faster Phenom (amd2) since this soft is the heaviest of the chain. HAProxy runs on the Core2Duo (c2d). The web server runs on the smaller Athlon (amd1). Connections are point-to-point since I still have no 10GbE switch (donations accepted ;-)). Haproxy is configured to use kernel splicing in the response path :
listen http-splice bind :8000 option splice-response server srv1 1.0.0.2:80
Here is a photo of the machines connected together.
{kind=link}
Tests methodology
-
A script calls the request generator for object size from 64 bytes to 10 megs. The
request generator continuously connects to HAProxy to fetch the selected object from
the server in loops for 1 minute, with 500 to 1000 concurrent connections. Statistics
are collected every second, so we have 60 measures. The 5 best ones are arbitrarily
eliminated because they may include some noise. The next 20 best ones are averaged and
used as the test's result. This means that the 35 remaining values are left unused. This
is not a problem because they include values collected during ramping up/down. In
practise, tests show that using 20 to 40 values report the same results. Note that
network bandwidth is measured at the HTTP level and does not account for TCP acks nor
TCP headers. Other captures at the network level show slightly higher throughput.
-
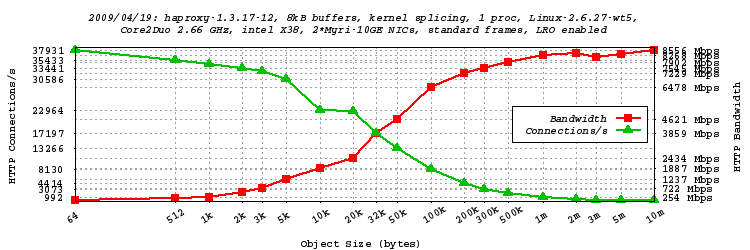
The collected values are then passed to another script which produces a GNUPLOT script,
which when run, produces a PNG graph. The graph shows in green the number of hits per
second, which also happens to be the connection rate since haproxy does only one hit
per connection. In red, we have the data rate (HTTP headers+data only) reached for
each object size. In general, the larger the object, the smaller the connection
overhead and the higher the bandwidth.
Tests in single-process mode, 8kB buffers, TCP splicing, LRO enabled, Jumbo frames
-
In this test, we configure haproxy to use the kernel's splicing feature to
directly forward the HTTP response from the server to the client without copying
data. The network interfaces MTU default to jumbo frames (9000 bytes). Large Receive
Offload (LRO) is enabled by default on these NICs too, which results in larger segments
being processed at once. Both network interrupts are sent to CPU core 1, and haproxy is
running alone on CPU core 0. This is how I have achieved the highest throughput to date.
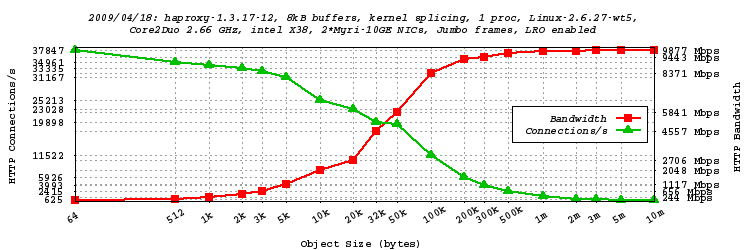
A total of 19 objects sizes from 64 bytes to 10 MB have been tested :
-
We can see that now even with only one haproxy process we have no problem reaching the 10 Gbps.
Network measures have shown 9.950 Gbps of forwarded traffic on the client interface for
all object sizes larger than 1 MB, which was not possible at all in earlier version without the
help of kernel-based TCP splicing. Also the session rate has increased a lot to reach a peak of
38628 sessions/s as seen on the stats page below during the test. This is 55% more
than one year ago on the same hardware ! One can notice that the gigabit is reached for
objects larger than about 4kB, which is a lot better than what is observed with more common
gigabit NICs.
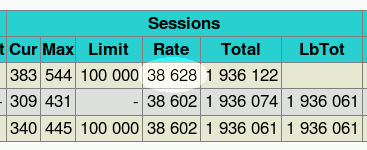
The CPU usage has dropped a lot since the introduction of LRO and TCP splicing. Forwarding 9.95 Gbps of Ethernet traffic consumes less than 20% of the CPU :
root@c2d:tmp# vmstat 1 procs memory swap io system cpu r b w swpd free buff cache si so bi bo in cs us sy id 1 0 0 0 1951376 3820 19868 0 0 0 0 25729 23965 1 15 84 0 0 0 0 1950652 3820 19868 0 0 0 0 25744 23818 3 17 80 0 0 0 0 1950632 3820 19868 0 0 0 0 25720 24652 1 18 80 0 0 0 0 1949512 3820 19868 0 0 0 0 25531 24047 3 16 81 1 0 0 0 1948484 3820 19868 0 0 0 0 25911 22706 2 19 79 0 0 0 0 1949388 3820 19868 0 0 0 0 26189 23757 3 15 82 1 0 0 0 1948460 3820 19868 0 0 0 0 25811 23766 1 20 79
Tests in single-process mode, 8kB buffers, TCP splicing, LRO enabled, standard frames
-
Most people cannot enable jumbo frames on the client side because they're connected to
the Internet and the 'Net is not jumbo-friendly. However, since haproxy is a proxy, it
can be used as a jumbo frame converter, reserving jumbo frames for the internal
network, while the external network runs at 1500. This test has been performed with
MTU=1500 on the client network.
Concerning the CPU usage, at full load (9.2 Gbps at 1500-byte frames), the CPU usage was extremely low : 2% user, 15% system. That means that the LRO feature of the Myri-10G NIC is extremely efficient at offloading the system :
root@c2d:tmp# vmstat 1 procs memory swap io system cpu r b w swpd free buff cache si so bi bo in cs us sy id 0 0 0 0 1811764 3820 19844 0 0 0 0 26289 19089 2 14 84 0 0 0 0 1787924 3820 19844 0 0 0 0 26268 19578 1 13 86 1 0 0 0 1772704 3820 19844 0 0 0 0 26288 18517 3 13 84 0 0 0 0 1774260 3820 19848 0 0 0 0 26284 19522 2 15 83 1 0 0 0 1766144 3820 19848 0 0 0 0 26260 19042 3 15 83 1 0 0 0 1734412 3820 19848 0 0 0 0 26270 18603 4 15 81 0 0 0 0 1719864 3820 19848 0 0 0 0 26294 18886 1 14 85
Session setup/teardown rates
-
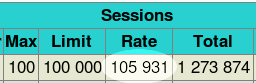
It is interesting to see how many sessions setup/teardown haproxy supports in various
modes. This is important for people who want to protect against attacks for example, or
support extreme loads. First test consisted in modelizing an ACL blocking requests at
the TCP inspection stage :
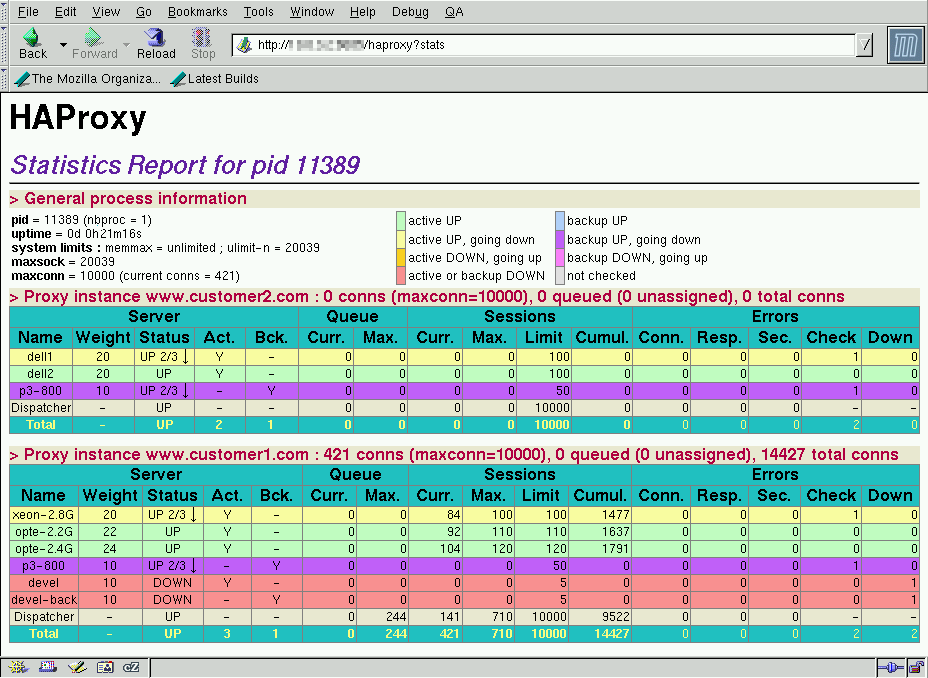
acl blacklist src 1.0.0.0/8 tcp-request content reject if blacklistNote that this filter applies before HTTP request parsing. Well, the result was beyond my expectations, I had to use the two AMD systems to attack haproxy to get a score, but I couldn't saturate the CPU, which remained below 75% used. The session rate has broken the symbolic 100k/s barrier with 105931 sessions per second !
HTTP session rate
Many other people are interested in the HTTP session rate on the client side. The difference with previous test is that we have to completely parse the HTTP request before taking a decision. There are a number of circumstances where a client request may not be routed to a server after being parsed. This happens when the request is invalid, blocked by ACLs or redirected to an external server. So in order to make the test the most representative of real usage, the configuration has been set to perform a redirect when an ACL detects that the local servers are being shut down for maintenance :
acl service_down nbsrv -lt 2 redirect prefix http://backup.site if service_downThe session rate was still very high : 82702 HTTP requests per second with about 20% CPU remaining available (eg for logging) :
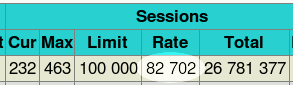
What's really interesting here is that the user CPU usage oscillates between 23 and 30%, meaning that the HTTP parser takes less than one third of a core to process 82700 requests/s. This extrapolates to a potential of about 250-300000 HTTP requests per second being processed when keep-alive is supported. Of course this does not take into account the added work induced by network traffic.
Conclusion
-
The first conclusion of those three tests is that the Linux 2.6 kernel, the Myri10GE
driver and HAProxy have improved a lot since last year's tests. It is now possible to
run at 10GbE line rate with one single process without consuming much CPU power, with or
without jumbo frames, and that's a great news. 10GbE becomes mature. Some tests on
various NICs tend to indicate that the kernel splicing is not always interesting,
especially with dumb NICs. But the carefully designed ones really benefit from this
feature. The Myri-10G NIC certainly is one of those. David Miller, the maintainer of the
Linux networking says that Sun's Neptune chip is another excellent one. I have not had
the opportuniy to give it a try though. Anyway, I would only recommend such well-designed
NICs to anyone who seriously considers switching to 10GbE speeds on a single machine.
Large objects are still required to fill 10GbE (at least 1MB average). That is totally
compatible with file sharing or online videos. For people with a mixed traffic, targetting
3-4 Gbps with files averaging around 30 kB would be more realistic (which is still 15-20000
sessions per second).
Another nice feature set is haproxy's ability to act as an MTU converter for 10GbE networks. Alteon did that 10 years ago to permit 1500 and 9000 bytes MTU to coexist on gigabit networks. Now the same issue happens with 10GbE. Some servers will be set to use jumbo frames but the outer networks will not support them. Setting haproxy in full transparent mode between two interfaces should help a lot. Note that the same could be true for IPv6/IPv4 translation at full line rate.
- revisit last year's benchmarks
⇐ Back to HAProxy
Contacts
Feel free to contact me at for any questions or comments :
- Main site : http://1wt.eu/
- e-mail :